
La inteligencia artificial ha escalado a un nuevo nivel de automatización: kernels CUDA generados por IA están demostrando superioridad en rendimiento sobre PyTorch en múltiples pruebas de aprendizaje automático. Este avance marca un punto de inflexión donde la IA optimiza directamente su propia infraestructura computacional, prometiendo acelerar los workflows de entrenamiento e inferencia empresarial.
Automatización inteligente de kernels GPU
Frameworks como Sakana AI’s AI CUDA Engineer están automatizando la conversión de código PyTorch a kernels CUDA optimizados, logrando mejoras de rendimiento de 10-100x sobre operaciones estándar de PyTorch. Esta automatización escalable elimina la necesidad de programación manual de kernels, tradicionalmente un proceso complejo que requiere expertise especializado en arquitectura GPU.
La tecnología utiliza modelos de lenguaje avanzados junto con optimización evolutiva, aplicando estrategias de “supervivencia del más apto” para identificar y refinar automáticamente los kernels más eficientes.
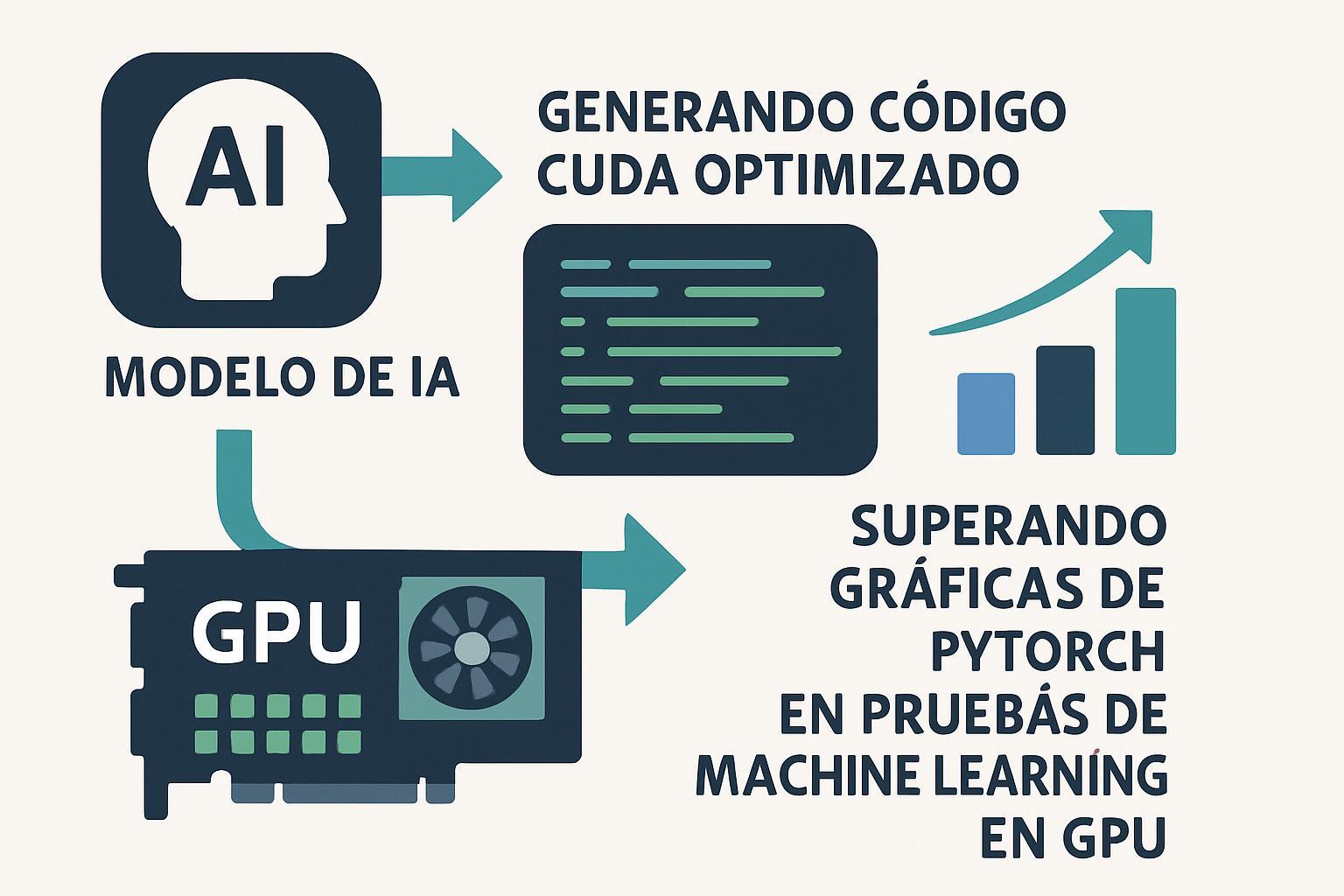
Impacto en operaciones empresariales
- Reducción de costes computacionales: Mejoras de 20-30% en GPUs NVIDIA y hasta 100% en AMD MI300X/MI325X
- Aceleración de desarrollo: Eliminación de semanas de optimización manual de kernels
- Democratización del rendimiento: Acceso a optimizaciones avanzadas sin expertise especializado
- Escalabilidad automática: Adaptación dinámica a diferentes configuraciones de hardware
Técnicas de optimización aplicada
Los kernels generados por IA implementan múltiples estrategias de optimización simultáneamente:
- Gestión optimizada de memoria: Movimiento eficiente entre jerarquías de memoria GPU
- Paralelización inteligente: Maximización de warps activos para ocultar latencias
- Precisión adaptativa: Uso automático de tipos de datos de menor precisión (FP16, BF16)
- Operaciones asíncronas: Solapamiento de transferencias de memoria con computación
Integración en flujos de trabajo existentes
La implementación se integra directamente con el pipeline TorchInductor, permitiendo que empresas adopten estas optimizaciones sin modificar significativamente sus flujos de trabajo actuales. Sistemas como Mako emplean algoritmos de búsqueda inteligente con aprendizaje por refuerzo para identificar configuraciones óptimas automáticamente.
Esto representa un avance crucial para equipos que buscan optimización de procesos sin invertir recursos substanciales en reentrenamiento técnico especializado.
Aplicabilidad en entornos de producción
Las primeras implementaciones demuestran resultados consistentes en benchmarks como KernelBench, validando el procesamiento contextual de estos sistemas para adaptarse a diferentes cargas de trabajo de machine learning.
La tecnología permite que organizaciones aprovechen mejoras significativas en eficiencia computacional, traduciendo directamente en reducción de costes operativos y tiempos de entrenamiento más cortos para modelos de IA empresariales.

